Le problème ne venait pas du site
Quand Google Search Console affiche une erreur d’exploration, le premier réflexe est souvent de regarder ses propres fichiers : le robots.txt, le sitemap, les redirections, le fichier .htaccess, les pages PHP, les liens internes ou la configuration générale du site.
C’est logique. Un webmaster sérieux commence par vérifier son propre travail. Dans mon cas, pourtant, le site était léger, le fichier robots.txt existait, les pages répondaient, et rien n’indiquait une erreur volontaire de configuration côté JMCBoost.fr.
Le signal inquiétant venait d’ailleurs : Google Search Console indiquait que Google n’arrivait pas à atteindre le fichier robots.txt, alors que ce même fichier restait accessible manuellement depuis un navigateur classique.
Le signal dans Google Search Console
La capture ci-dessous montre le problème tel qu’il apparaissait dans Search Console : l’outil d’inspection Google signalait un échec de récupération du fichier robots.txt. Pour un site qui dépend de l’exploration Google, ce type d’erreur n’est pas anodin.
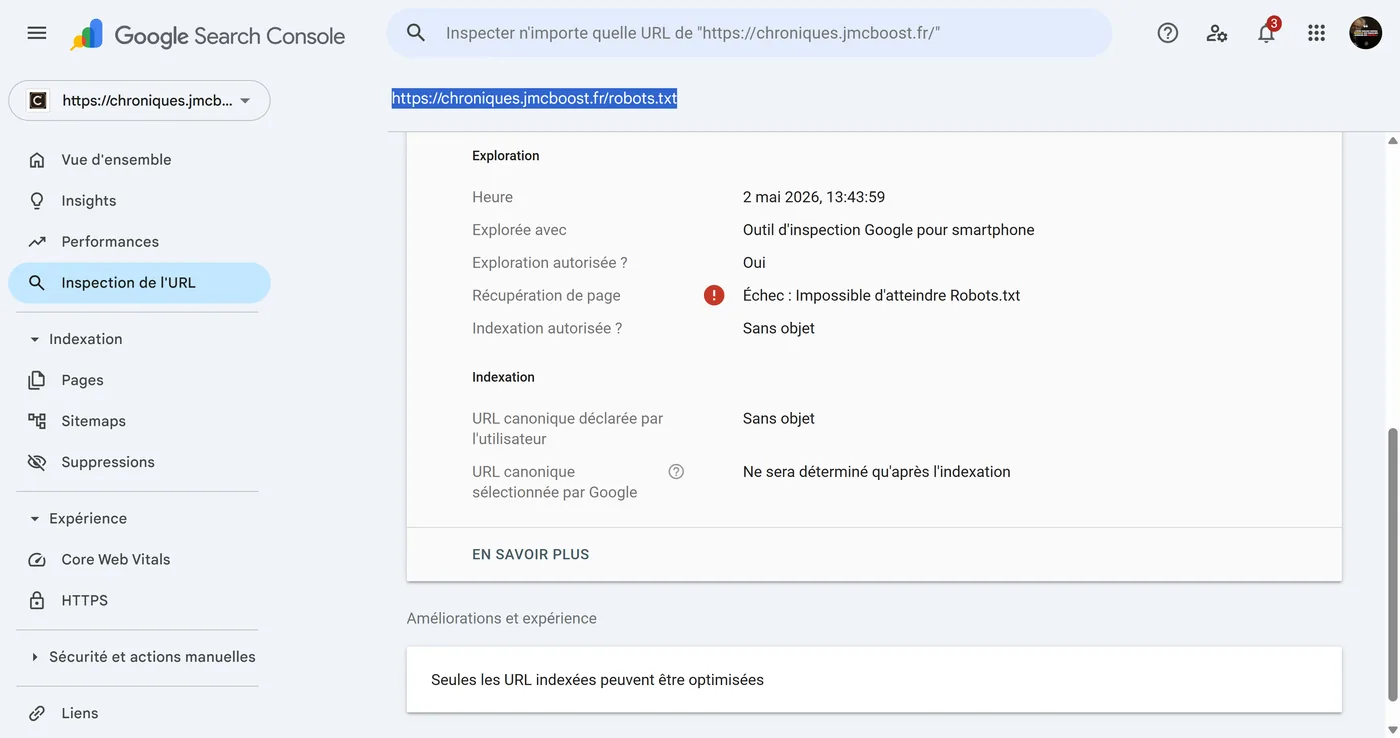
Ce genre de message peut avoir des conséquences concrètes : Google peut ralentir son exploration, reporter l’indexation, ou considérer temporairement que certaines pages ne peuvent pas être correctement analysées. Pour un site récent ou en construction, c’est particulièrement pénalisant, car chaque passage de Google compte.
Pourtant, le robots.txt était accessible
Le point important, c’est que le fichier n’était pas absent. Il n’était pas vide. Il n’était pas bloqué volontairement par une directive maladroite. Il s’ouvrait normalement depuis un navigateur.
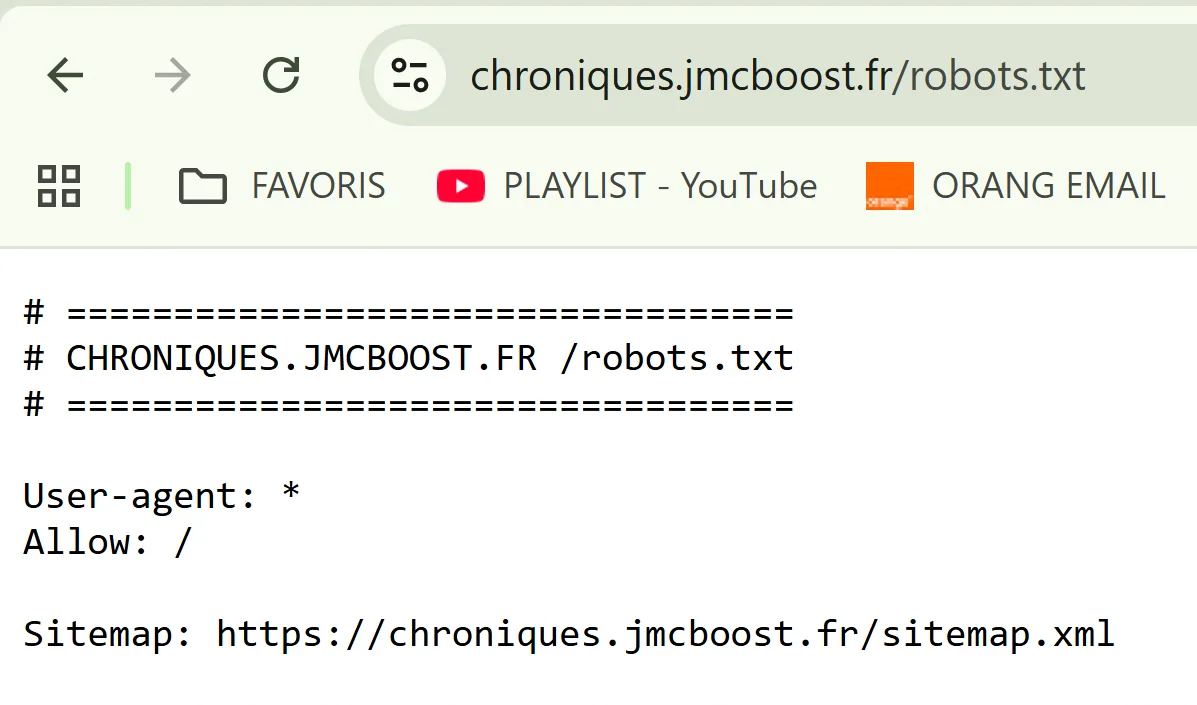
Cette contradiction est essentielle. Si un navigateur humain accède au fichier, mais que Google Search Console échoue, il faut regarder au-delà du simple fichier. Le problème peut venir d’un filtrage, d’un pare-feu, d’une règle serveur ou d’un comportement d’infrastructure qui ne touche pas forcément tous les visiteurs de la même façon.
La réponse côté hébergeur : le pare-feu
Après échange avec le support OVHcloud, la réponse technique a confirmé l’orientation du diagnostic : un administrateur avait mis à jour les règles du pare-feu, et Googlebot ne devait désormais plus être impacté sur l’hébergement.

Autrement dit, le problème n’était pas simplement une impression. Il y avait bien un élément côté infrastructure qui pouvait perturber l’accès des robots Google. Une fois les règles corrigées, Google Search Console pouvait relancer l’exploration normalement.
Corrigé techniquement ne veut pas dire réparé commercialement
C’est là que la nuance devient importante. Oui, le problème a fini par être corrigé techniquement. Mais pour le client, cela ne règle pas tout.
Pendant ce temps, le site a envoyé de mauvais signaux à Google. Il a fallu ouvrir un ticket, vérifier les fichiers, faire des captures, suivre Search Console, relancer les validations, patienter, puis surveiller les pages concernées. Ce temps-là n’est pas virtuel. Il est réel.
À mes yeux, un dossier ne peut pas être considéré comme totalement résolu simplement parce que le dysfonctionnement technique a été supprimé. La correction est la moindre des choses lorsqu’un service payé n’a pas fonctionné correctement. La réparation commerciale, elle, est un autre sujet.
Dans ce cas précis, je n’ai obtenu aucun geste commercial. Le problème a donc été corrigé côté technique, mais pas réparé dans ses conséquences : perte de temps, inquiétude SEO, surveillance supplémentaire et impact potentiel sur l’exploration du site.
Un site léger ne devrait pas donner cette impression de lenteur
Ce problème s’ajoute à une impression plus générale : même avec un site léger, sans usine à gaz, sans CMS lourd et sans base de données complexe, la rapidité n’a jamais donné une impression exemplaire.
Je ne peux pas affirmer une intention commerciale derrière chaque lenteur. En revanche, côté utilisateur, quand un site simple reste lent et que les offres plus performantes sont naturellement mises en avant, la question de la qualité réelle de l’hébergement de base se pose forcément.
Un petit site propre ne devrait pas avoir besoin d’une offre disproportionnée pour répondre correctement. La base d’un hébergement payé, c’est d’abord d’être stable, accessible et suffisamment rapide pour servir des pages simples sans compliquer la vie du webmaster.
Ce que cette expérience rappelle aux webmasters
Ce retour d’expérience rappelle une chose simple : quand Google signale un problème d’exploration, il ne faut pas accuser son site trop vite. Il faut vérifier méthodiquement, mais il faut aussi garder en tête que le problème peut venir de l’hébergement, du firewall ou d’une règle serveur invisible depuis l’extérieur.
- Tester l’URL dans Google Search Console.
- Comparer avec un accès direct depuis un navigateur.
- Conserver les captures avec dates visibles.
- Demander une confirmation technique écrite au support.
- Relancer l’exploration seulement après correction.
- Ne pas modifier inutilement un site sain pour compenser une erreur d’infrastructure.
Le vrai problème, ce n’est pas seulement la panne
Un incident technique peut arriver. Aucun hébergeur n’est à l’abri d’un mauvais réglage, d’un filtrage trop strict ou d’une règle de pare-feu mal ajustée. Le vrai sujet, ensuite, c’est la manière dont l’incident est reconnu, expliqué et assumé.
Dans mon cas, le site n’était pas en cause. Le fichier robots.txt était accessible. Google, lui, rencontrait un blocage. OVHcloud a fini par corriger les règles du pare-feu. Mais la correction technique ne supprime pas le temps perdu, ni l’impact potentiel sur l’indexation, ni l’absence de geste commercial.
Pour JMCBoost.fr, cette expérience restera une preuve utile : parfois, un site propre peut être pénalisé par ce qui l’héberge. Et dans ce cas-là, le webmaster doit documenter, garder les captures, demander des réponses précises et ne pas se laisser renvoyer trop vite vers ses propres fichiers.